Literate Modeling with org-model
Table of Contents
I believe that the time is ripe for significantly better documentation of programs, and that we can best achieve this by considering programs to be works of literature. Hence, my title: "Literate Programming."
Let us change our traditional attitude to the construction of programs: Instead of imagining that our main task is to instruct a computer what to do, let us concentrate rather on explaining to human beings what we want a computer to do.
— Donald Knuth (Knuth, Donald Ervin, 1984)
Having employed MDE techniques extensively for over a decade, we became keenly aware of the importance of both the medium and tooling with which to compose and edit models, as well as of the significance of its integration with the remainder of the software engineering stack. This chapter concerns itself with org-model, a new technology developed within MASD that benefits from lessons learned and is designed specifically to satisfy our modeling use cases. Org-model marks MASD's internal departure from graphical representations, and underlines a new emphasis on textual representations and literate modeling.1
The chapter is organised as follows. Section Motivation motivates the need for a new approach, and points to the general direction in which to follow. Section Literature Review performs a brief literature review on the topic, with particular attention paid to literate modeling.2 An overview of org-mode is then provided by Section Overview of org-mode, and org-model — a solution built atop of it — is put forward by Section Creating the org-mode codec. The chapter ends by discussing the benefits and drawbacks of the new approach (Section Evaluation). Let's start by looking into why a change was necessary in the first place.
Motivation
Pervasive integration with development tooling is one of MASD's core tenets (the Integration Principle). As the previous sections alluded to, great care was taken in creating a codec representation, specifically designed to facilitate tooling integration (cf. the Domain Architecture chapter). The idea is to lower barriers to entry, allowing bindings to any modeling tool used by developers. The initial expectation was that extraction — i.e. projections from external TSs into MASD — would entail parsing a file format in JSON or XML, preferably XMI (cf. State of the Art in Code Generation), because UML was seen as the obvious language for model editing. For the majority of MASD's lifespan, Dia3 has been used in this regard. Dia is a general-purpose FOSS diagramming tool, with support for UML amongst great many other notations. Figure 1 shows Dia with a fragment of a model from MASD's MRI.
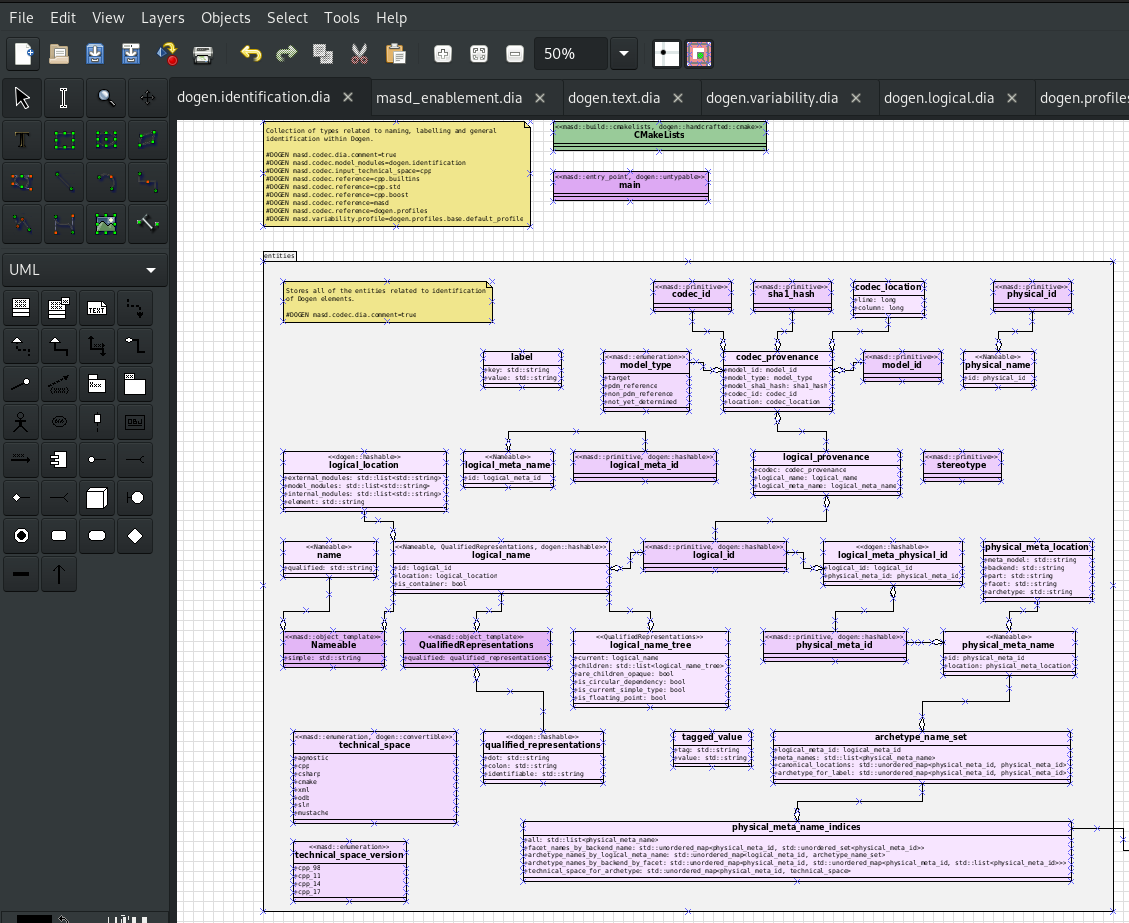
Figure 1: Dia modeling tool with a MASD model.
From a perspective of industrial-grade modeling, Dia suffers from significant deficiencies: it has limited understanding of UML — not much beyond seeing it as a set of shapes — and supports several core features in an inconsistent manner. For example, model-level stereotypes and tagged values are not available, though they exist for other elements — hence why these have been added to UML notes via a MASD-specific extension, as demonstrated in Figure 1 (top-left, in yellow). That said, these limitations were incidental to MASD because our express intent is to avoid coupling the domain architecture to any one tool, and to use tooling merely as a means for model composition. In other words, the richer the feature set of the tool, the higher the risk of creating unwanted dependencies between it and MASD; conversely, having basic UML support acts as a mitigating factor.
Nevertheless, after over a decade of extensive Dia usage, an unexpected conclusion was reached: the tool had begun to have a restrictive impact in MASD's development, and on the MRI in particular (cf. MASD Reference Implementation). A reflection on the challenges faced revealed that these issues were not related to Dia per se but were instead properties of graphical modeling in a MASD context — all the more noticeable because models are central to our work.4,5 Whilst a graphical representation aids comprehension — particularly when carefully curated and aided by colour schemes, as is done in the MRI — a large proportion of the modeling work is related to editing elements and their properties. Often times it entails going backwards and forwards between different representations, as depicted by Figure 2.
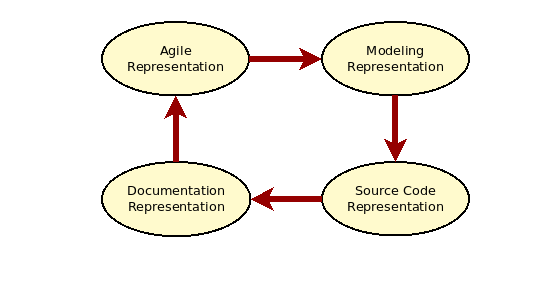
Figure 2: Information flow across representations in MASD.
The image provides a simplified view of information flows across representations within the MRI, as observed during the development of new features.6 Typically, one begins with a textual representation in natural language, captured as a user story during an agile sprint. The story may evolve over time, remaining in analysis until mature and ready for implementation. At this stage, the story is often then modeled in a graphical representation (i.e., Dia), and one begins to iterate between it and a source code representation during one or more sprints. Finally, as the story nears completion, work commences on updating the documentation in light of the changes it brought about, which in turn may spur the development of new and related stories, change the understanding of existing stories, and so forth, in a continuous loop that lasts the lifetime of the software product.
With the exception of modeling, all representations are in a textual form. Thus, an obvious way in which to reduce friction in information flow is to decrease the impedance mismatch between representations; this can be achieved by normalising them all to a similar textual form. To understand how best to go about this, we consulted the literature.
Literature Review
Our views on the limitations of graphical representations are amply echoed within the literature, such as by the work of Arlow et al. (Arlow, Jim and Emmerich, Wolfgang and Quinn, John, 1998), subsequently augmented by (Arlow, Jim and Neustadt, Ila, 2004). There, Arlow et al. substantially advanced our own diagnosis:
One problem you will find with UML models (and in visual models in general) is that the valuable information captured in the model is only accessible to those who know the visual syntax of the modelling language. In a sense, valuable information about the business becomes encrypted in a concise, elegant modelling language […].
In fact, it is not just the visual syntax of UML models that creates problems. If you need to access the information embedded in a model, you may also need to know how to work a CASE tool to navigate that information effectively. […]
Also, unless you already know the general "shape" of a model, knowing precisely where to start with either the model in a CASE tool, or with a generated report can be difficult. (Arlow, Jim and Neustadt, Ila, 2004) (p. 88)
Moreover, their suggestion on how to address these issues pointed towards literate modeling, which resonated closely with MASD's needs:
Literate modelling applies of Knuth's idea of Literate Programming (Knuth, Donald Ervin, 1984) to UML models. The approach is very simple — you interleave UML models with a narrative text that explains the model to both the author of the model and to all the roles discussed above [e.g., the actors involved in the development process].
Whilst in overall agreement with their diagnosis, we nonetheless disagreed with the proposed solution, preferring a text-only approach over the suggested content interleaving. Text was then the direction of travel, but there was still an important decision to be made with regards to the specific notation to employ. Research on textual representations for modeling languages has a prolific presence in the literature; our excursion uncovered approaches such as Model-Oriented Programming (MOP) — the work of Badreddin and Lethbridge being of particular interest (Badreddin, Omar and Lethbridge, Timothy C, 2013), as well as Executable UML (Mellor, Stephen J and Balcer, Marc and Foreword By-Jacoboson, Ivar, 2002). However, the requirements of MASD directed us away from such complex endeavours since models within MASD cater only for structural aspects, with simpler behaviours encoded in the geometry of physical space (cf. the Domain Architecture chapter). In this light, complex behaviour is entirely relegated to the programming language representation, thus negating the main advantages of an expressive modeling language in the vein of MOP.
In addition to the more comprehensive MOP languages, a host of lightweight representations was also found, including MetaUML7, TextUML8, PlantUML9, yUML10 and others of a similar ilk, all characterised by a compact scope and a focus on outputting diagrams as images; one could conceivably target the structural subset of any one of these implementations to satisfy MASD's requirements. Alas, by carefully observing MASD's information flow (Figure 2), these approaches were seen to be better suited for extractive projections out of MASD rather than as injections. It is so because both the agile representation and the documentation representation involve natural language; the literate modeling approach is closer to either of these two representations than it is to the source code representation.11
The analysis of information flows also revealed that both MASD's documentation as well as its agile processes rely extensively on org-mode12, a textual representation available in the Emacs editor used for MRI development — but also supported by a host of other editors and IDEs.13 Org-mode had been shown to be a competent environment for literate programming and reproducible research by Schulte et al. (Schulte, Eric and Davison, Dan and Dye, Thomas and Dominik, Carsten and others, 2012); its tree-like structure and support for annotations provide ample scaffolding with which to map all of the modeling constructs required to represent UML constructs.
Furthermore, as Schulte et al. had already noticed, org-mode has a broad and diverse tooling ecosystem that can be applied directly to both modeling and the weaving of MASD's information flow. The following should suffice as a demonstration of the strength of the tooling ecosystem: org-roam14 augments org-mode with support for zettelkasten15; org-brain16 adds support for concept mapping17; and org-ref18 manages citations, cross-references, indexes, glossaries and bibliographies for org-mode documents.19 These are all useful tasks in a modeling environment driven by literate modeling and DDD (cf. The MASD Methodology). With this in mind we begun to explore the possibility of modeling using org-mode documents. But before delving into how this was achieved, we shall first provide a brief overview of org-mode.
Overview of org-mode
There are a great number of markup languages widely used in software development, starting with arguably the most known of all, HTML.20 Whilst org-mode is part of the family of markup languages, it distinguishes itself due to a deep integration with the Emacs editor (Stallman, Richard M, 1981) and its programming language Emacs Lisp (Lewis, Bil and LaLiberte, Daniel and Stallman, Richard and others, 1993). In the previously mentioned paper, Schulte et al. convey enthusiastically both the simplicity and the power of this combination (emphasis ours):
As org-mode is well documented, physical modeling (cf.
The MASD Methodology) relied on existing sources such as
({Org Syntax}, 2021). Two brief examples will be shown to demonstrate the
morphology of org-mode files. Figure 3 displays a
fragment of a sample org-mode document, as sourced from the previously cited
project's website.12 The document is at the centre, with a darker
background; to its left and right are annotations to help identify elements and
features. The outline structure of org-mode is created via the star or asterisk
character (*), with the number of stars conveying depth — shown in the
picture with headlines of varying colours.
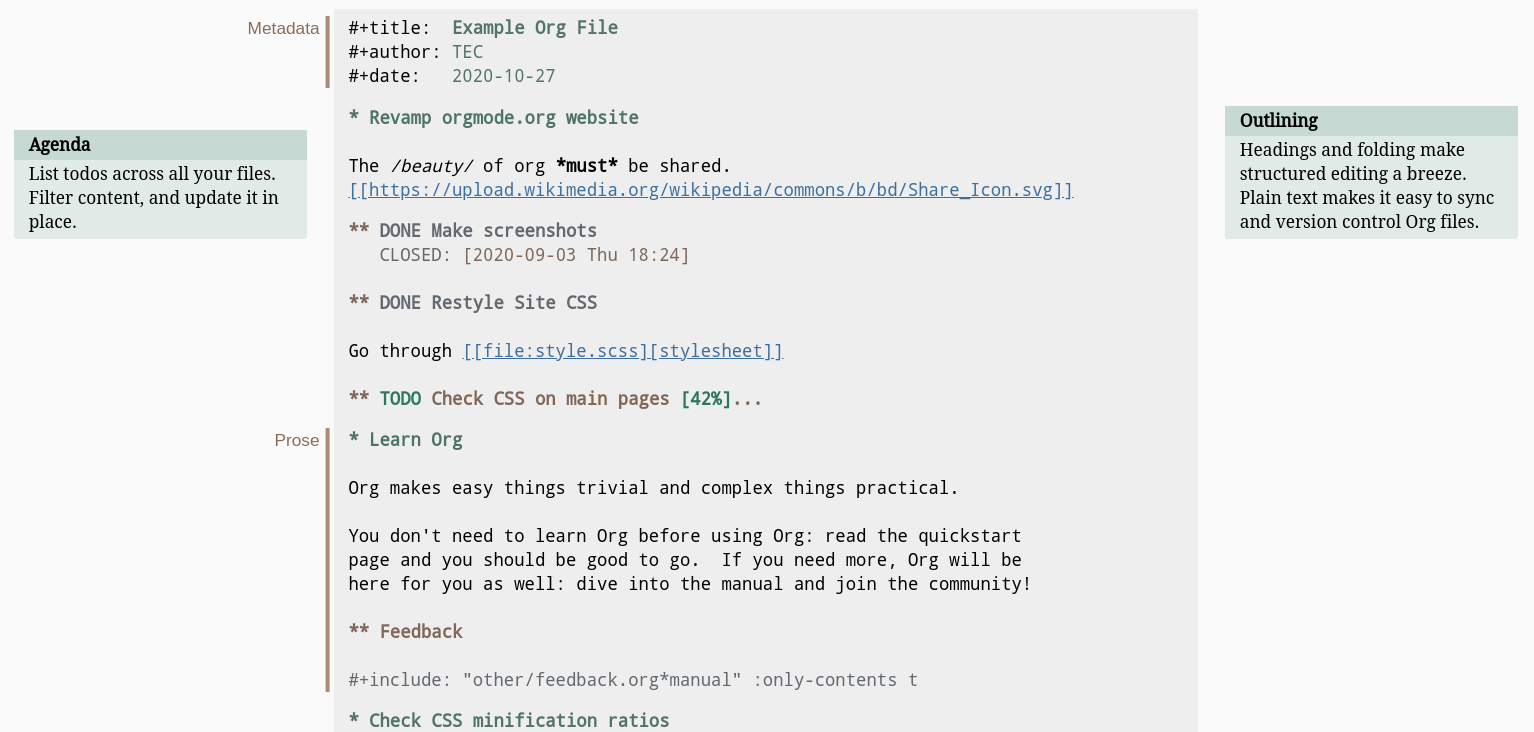
Figure 3: Fragment of example org-mode document. Source: Project website.
Different kinds of metadata can be associated with the document — such as
title, author and date, top left — as well as task management
annotations — for example, the so called TODO keywords are in upper case,
such as TODO and DONE. In addition, though not shown in the picture, each
headline can have one or more associated tags, in the form :TAG_NAME:. Note
also how headlines can be folded, making them non-obtrusive (headline "Check
CSS on main pages"). Finally, the example also demonstrates a variety of
mechanisms for linkage to other sources of information: from HTTP links, to
links to arbitrary files in the filesystem, to including other org-mode
documents via the #+include keyword.
Our second example, also sourced from the org-mode website, demonstrates the
usage of source code blocks within a org-mode document (Figure
4). The #+begin_src keyword denotes the start of
the source code block, followed by the language used within the block (python
in this particular case). In addition to providing syntax highlighting relative
to the language used, org-mode also allows editing the source code block within
an environment that is similar — if not exactly identical — to a full
programming environment, with access to IDE-like features such as code
completion, compilation errors and the like.
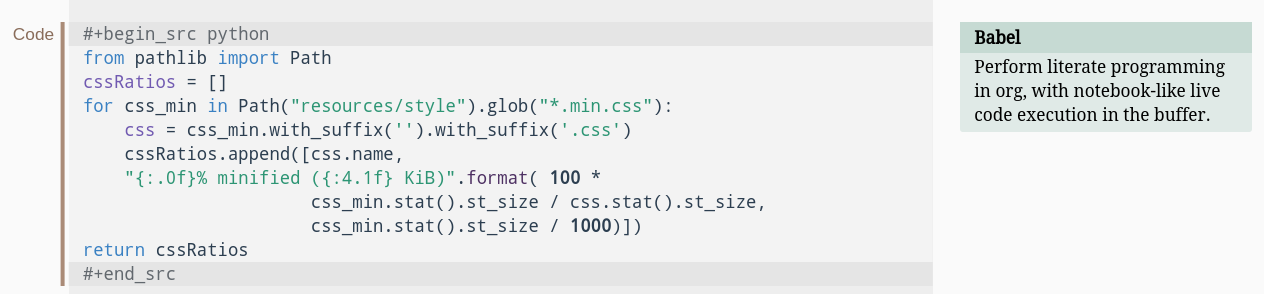
Figure 4: Fragment with source code blocks. Source: Project website.
The third and final example focuses on property drawers. Documents, headlines
and other org-mode elements can be associated with an arbitrary number of
properties. As with headlines, these can be kept open or folded away for
convenience. Figure 5 demonstrates the use of
property drawers, both at the document level, as well as at the headline level.
In the example, we show the ID property associating a UUID with each element,
including the document itself (at the top). One of the property drawers is
folded away (headline "Example sub-headline collapsed"). For completeness, we
also created a sample property called MY-PROPERTY that is only associated
with the top-most headline "Example headline".
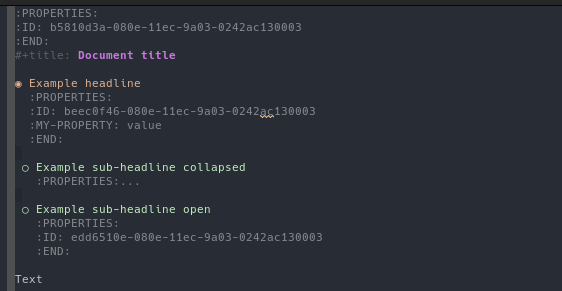
Figure 5: Org-mode document with property drawers.
This brief overview portrays only a sliver of org-mode's power and abilities. Nonetheless, these examples demonstrate all of the core features needed by MASD in order to store its models within an org-mode document. The next section shall now explain how this was achieved.
Creating the org-mode codec
Given that the purpose of the new codec was to introduce org-mode based
modeling, we decided to name it org-model.22 The first step
to introducing a new codec to MASD involves locating an existing platform
library that can parse files of this format, implemented on the TS of choice for
the MRI (C++). As mentioned before, there had been an expectation that input
formats for codecs would be in JSON, XML or other popular data interchange
formats, for which there are many supporting libraries, providing adequate
platforms from which to work from. For org-mode, the number of choices was very
limited; few libraries could be located, and of those only
OrgModeParser23 was of industrial grade quality, with support
for all the required features. Unfortunately, its large number of dependencies
and sparse maintenance made it incompatible with the approach used in the MRI.
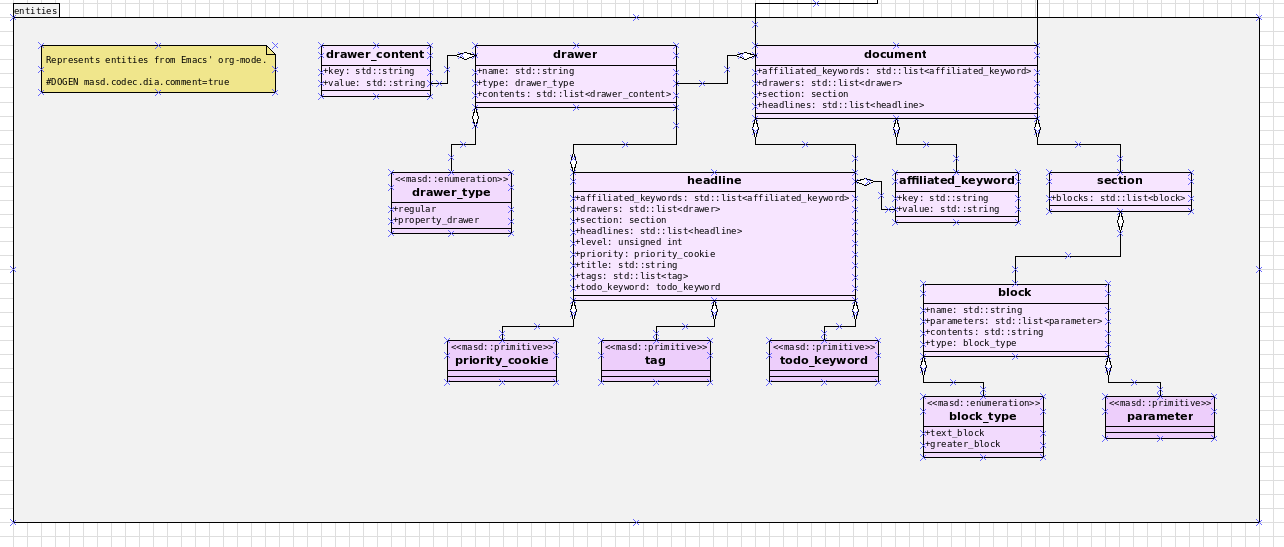
Figure 6: Dia representation of org-mode model.
Having no other alternative, we implemented org-mode support by extending the MRI. This was done by creating a component model to store all of the data structures required by the codec (Figure 6), and writing a parser that reads input files in org-mode notation and instantiates entities with MASD's org-mode model. Thanks to the codec pipeline, the integration of the org-mode model with the remainder of the framework was quite straightforward, and required only two trivial M2T transforms that are specific to org-mode. The key decisions were related to the mapping of the modeling elements to the org-mode document elements, which we shall now describe.
The mapping was surprisingly simple:
- The org-mode document itself was mapped to a model. Its stereotypes and tagged values are supplied as properties in the document-level property drawer.
- Headlines were mapped to different modeling elements, depending on their tags.
We mapped each meta-element in the codec model to its own tag:
module,elementandattribute. - Finally, the content of the headline was used to populate the comment for the codec element.
The mapping can be seen in action on Figure 7, depicting an org-mode representation of the org-mode model previously shown in its Dia incarnation (Figure 6). The property drawers have been left open for illustrative purposes but, even in their expanded state, it should be apparent how documentation now dominates the model when compared to its UML representation, taking us much closer to literate modeling without subverting the org-mode file format.
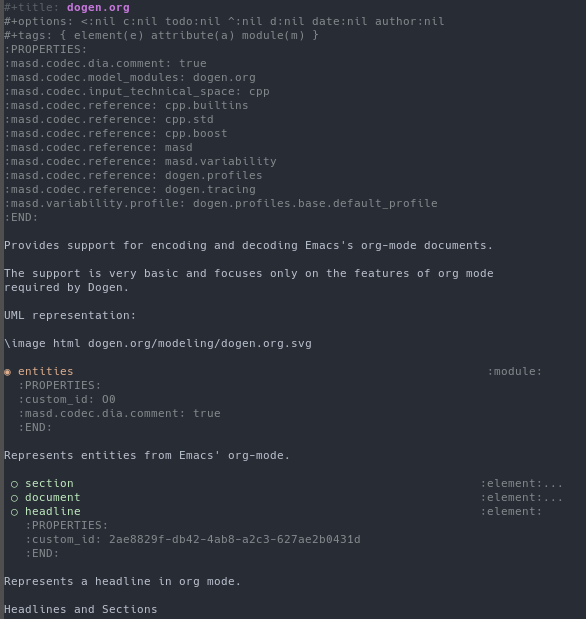
Figure 7: Org-mode model in org-mode notation.
This outcome was not completely left to chance. Indeed, a key principle when
designing the mapping was to try to keep to org-mode's native idioms as much as
possible, so that MASD models would not appear surprising to regular (i.e.
non-MASD) org-mode users. The advantages extend beyond humans since such an
approach also ensures compatibility with the tooling ecosystem. However, note
that the mapping is not completely native as of yet, with further analysis work
still ongoing; for example, references could make use of links to facilitate
navigation between org-mode documents, but at present these are properties
within the model drawer (e.g. masd.codec.reference in Figure
7, near the top).24
A final note is warranted on the processing of headline titles. In the interest
of pushing forward with the literate modeling agenda, titles can make use of
natural language conventions such as spaces and capitilisation, greatly
improving readability: e.g., "An example title" instead of
"an_example_title". Doing so means benefiting directly from org-mode's
extensive export machinery without requiring preprocessing — such that a model
generate documents in formats such as PDF, HTML and many others. Conversely,
for the purposes of code generation, headlines are converted internally into
valid identifiers, as a function of non-structural variability; for instance,
users can decide to replace spaces by underscores, camel or pascal casing as
well as other conventions popular with software engineers.
Evaluation
Introducing org-model into the MRI was a typical application of the MASD Composite Process (cf. The MASD Methodology). Consequently we must analyse the impact of the application at two distinct levels: application and meta-application. The first level is the most obvious: there was a practical requirement to address a set of diagnosed issues and, in doing so, a significant new feature was added to the MRI. However, the exercise was also a test on how the fundamental ideas of MASD are to be applied in the real world, and thus a meta-application of the methodology. The next two sections delve into the details of these two levels.
Application Evaluation
Though all models within MASD's MRI have been converted to the org-mode representation, this feature has been in production for less than a year, making it difficult to perform a thorough evaluation. Nonetheless, given the limitations previously had faced with graphical modeling, certain improvements are unequivocal:
- Improved information flow: it is clearly easier to move information between the different representations, particularly between the agile representation and the documentation representation as we had hoped. Having all documentation in the same format greatly helps in this regard.
- Improved tooling integration: in the past, it was very difficult to move models backwards and forwards between versions in version control. Though Dia stored diagrams in a text representation, its XML file format is quite verbose and clearly designed for machine consumption rather than human. With org-mode, it is now trivial to diff versions of models, and to synchronise them using the exact same tools we use to manage source code
- Better model navigation and editing: closely related to the previous topic,
it is now much easier to find and edit model elements — again, because we
are making use of the same tooling as for programming. For example, we often
use Unix tools such as
grep,sed,sortetc. to retrieve and manipulate information stored in models — something which was not possible in the past due to the complexity of the Dia file format; these issues are common to any XML-based file format, so XMI would be no different. - Text templating integration: org-mode source code blocks allowed us to integrate the text templates used to generate M2T transforms in a very natural way. These will be discussed in more detail on MASD Reference Implementation, but the example shown on Figure 8 demonstrates the principle. The templates are carried within source code blocks in org-mode documents, facilitating their editing and composition.
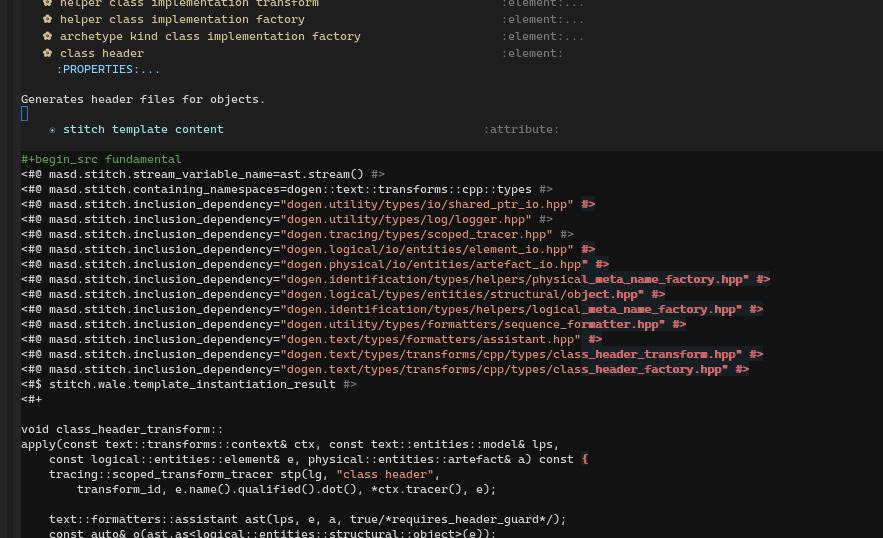
Figure 8: Example text template in a org-mode model.
However, not all aspects of this transition have been positive. By far, the most significant downside of moving towards a text representation was the loss of a graphical representation for modeling. Given that UML class diagrams had been very central to modeling within MASD, this was not an acceptable trade-off, so we decided to address this shortcoming by adding a PlantUML codec to the MRI. As Figure 9 attests, basic support for class diagrams is already available, though their expressiveness is not yet at the same level of past Dia diagrams.
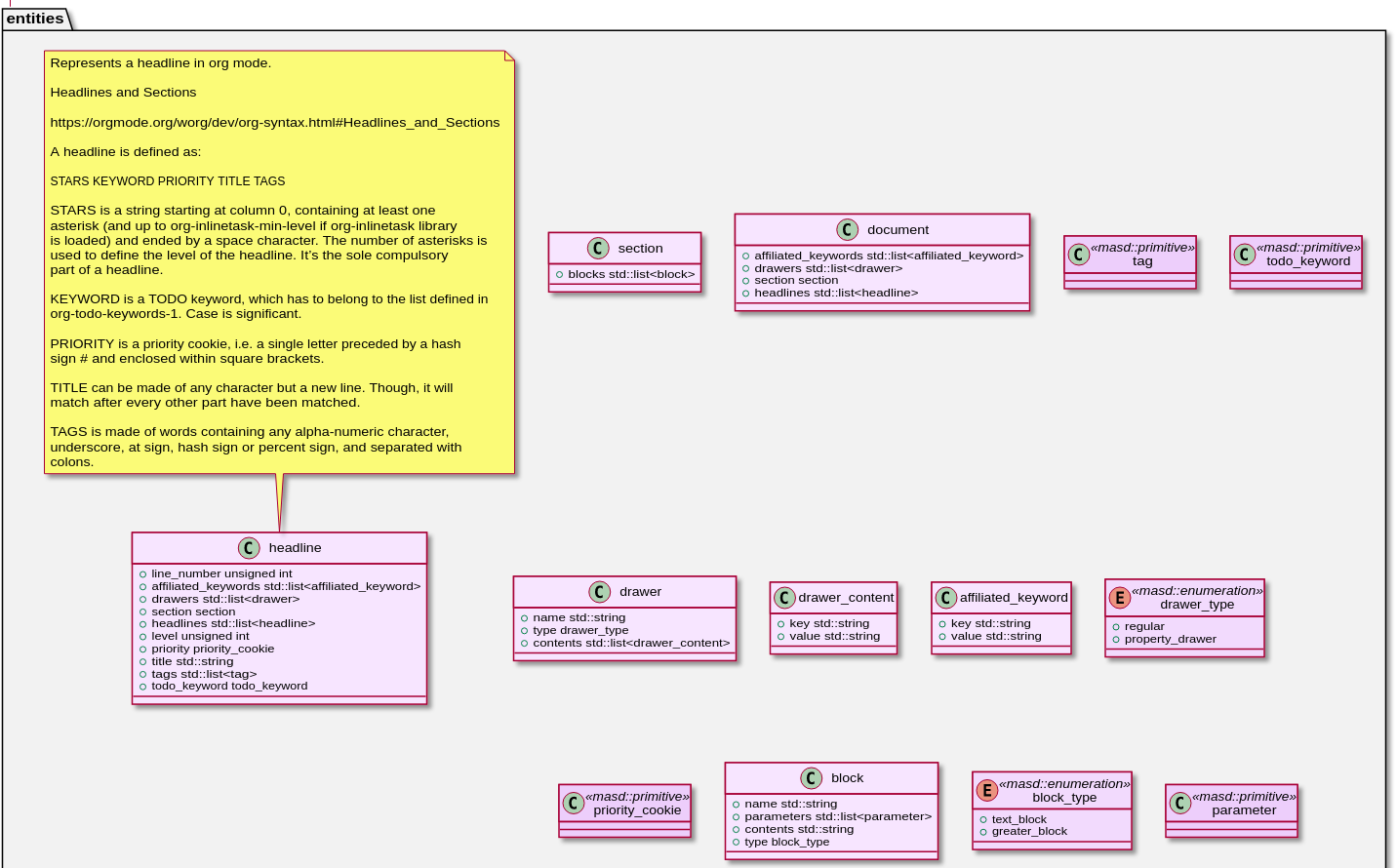
Figure 9: PlantUML representation of org-mode model.
Figure 6 had shown the Dia representation for a fragment of this very model. It should be apparent that the manually crafted diagram is "easier on the eye" when compared to the automatically generated PlantUML diagram, though the qualitative nature of this judgement makes it difficult to measure. Nonetheless, the easiness with which both org-mode and PlantUML codecs were added to the MRI validate the approach in creating a framework for codecs. They also make a broader statement with regards to pervasive integration, which the next section shall address.
Meta-application Evaluation
The implementation of org-model as a new feature in the MRI is a canonical example of how we expect MASD to change and adapt to developer workflows. By reflecting on the process, the following salient characteristics were found:
- Friction in the modeling process was detected. Parts of the development process had changed specifically to accommodate modeling, and demanded the use of tools that were not needed previously (i.e., Dia).
- Over a period of time, analysis was carried out on how to best perform the same modeling activities within the existing tooling; the aim was to discover a more efficient way of integrating the new processes with the existing development process, lowering the overall friction.
- Org-mode was chosen as the technology with the best fit with the current development environment. Physical modeling was applied to org-mode artefacts, even though their role was not to augment the PMM. This was not a use case we had anticipated for physical modeling, but it proved extremely useful.
- Additional use cases that had not been anticipated originally in MASD were made available by the new technological choice, with literate modeling being an important addition, as well as the many tools that make up the org-mode ecosystem.
Our conclusion is that the processes defined by MASD worked precisely as intended, and their application resulted in an overall improvement of the MRI.
Bibliography
Arlow, Jim and Emmerich, Wolfgang and Quinn, John (1998). Literate modelling—capturing business knowledge with the uml.
Arlow, Jim and Neustadt, Ila (2004). Enterprise patterns and MDA: building better software with archetype patterns and UML, Addison-Wesley Professional.
Badreddin, Omar and Lethbridge, Timothy C (2013). Model oriented programming: bridging the code-model divide.
Knuth, Donald Ervin (1984). Literate programming, Oxford University Press.
Lewis, Bil and LaLiberte, Daniel and Stallman, Richard and others (1993). GNU Emacs Lisp Reference Manual, Free Software Foundation.
Marco Craveiro (2021). Dogen v1.0.30, "Est{\'a}dio Joaquim Morais".
Mellor, Stephen J and Balcer, Marc and Foreword By-Jacoboson, Ivar (2002). Executable UML: A foundation for model-driven architectures, Addison-Wesley Longman Publishing Co., Inc..
Schulte, Eric and Davison, Dan and Dye, Thomas and Dominik, Carsten and others (2012). A multi-language computing environment for literate programming and reproducible research, Foundation for Open Access Statistics.
Stallman, Richard M (1981). EMACS the extensible, customizable self-documenting display editor.
{Concept map} (2021). Concept map — {W}ikipedia{,} The Free Encyclopedia.
{Markup language} (2021). Markup language — {W}ikipedia{,} The Free Encyclopedia.
{Org Syntax} (2021). Org Syntax — Org-mode project.
{Zettelkasten} (2021). Zettelkasten — {W}ikipedia{,} The Free Encyclopedia.
Footnotes:
To be clear, this chapter discusses MASD's internal modeling needs. Our approach may be suitable to others, wholesale, or merely seen as an experience report with restricted application. Either way, MASD remains strictly neutral with regards to its users' choice of tooling.
The topic is not without its representation in the literature, and certainly much could be said about it. However, given the role of this chapter in the present manuscript, the review was circumscribed to only items with a direct impact on our solution. Clearly, a thorough state of the art review would be beneficial, but its left as a future direction.
Note that our intention is not to make a general statement about graphical modeling — though, as our review of adoption literature points out, perhaps such a case can indeed be made (cf. State of the Art in Code Generation). Instead, our personal view is that textual modeling is better suited to our workflow, because, as software developers, manipulating text is at the core of our profession.
For a more detailed discussion on this subject, please consult the MRI's release notes when this feature was introduced. (Marco Craveiro, 2021)
For additional details on how agile is used in the MRI's development, see Software Development Methodology.
In other words, it is not the case that diagrams require contextual text; instead, the text describing a software product can be augmented by contextual diagrams.
At the time of writing, org-mode plugins were found for Visual Studio Code, Vim, Atom, and Sublime. Note that this is not an exhaustive list. However, not all features are supported and Emacs is still its reference implementation.
Wikipedia defines zettelkasten as follows: "The zettelkasten […] is a method of note-taking and personal knowledge management used in research and study. […] A zettelkasten consists of many individual notes with ideas and other short pieces of information that are taken down as they occur or are acquired." ({Zettelkasten}, 2021)
Wikipedia states that "A concept map or conceptual diagram is a diagram that depicts suggested relationships between concepts.[1] Concept maps may be used by instructional designers, engineers, technical writers, and others to organize and structure knowledge." ({Concept map}, 2021)
All of our research, including writing the present manuscript, was performed using org-mode, making ample use of org-mode's tooling ecosystem — for example for note taking, reference management, etc.
Wikipedia defines markup languages as follows: "In computer text processing, a markup language is a system for annotating a document in a way that is visually distinguishable from the content. It is used only to format the text, so that when the document is processed for display, the markup language does not appear." ({Markup language}, 2021)
At the core of Org-mode is the Emacs text editor and Emacs Lisp, a dialect of Lisp that supports the editing of text documents. […] Org-mode extends Emacs with a simple and powerful markup language that turns it into a language for creating, parsing, and interacting with hierarchically-organized text documents. Its rich feature set includes text structuring, project management, and a publishing system that can export to a variety of formats. Source code and data are located in active blocks, distinct from text sections, where "active" here means that code and data blocks can be evaluated to return their contents or their computational results. (Schulte, Eric and Davison, Dan and Dye, Thomas and Dominik, Carsten and others, 2012)
Since, for our purposes, we need not leverage all org-mode features, we shall only unpick those which are relevant to MASD. First and foremost, the hierarchical nature of org-mode is a great fit for MASD's modeling data, given its focus on structural modeling as emphasised constantly in the domain architecture (cf. the Domain Architecture chapter). Secondly, the support for source code interleaving is also of great interest to MASD, allowing us to carry fragments of code or even complete source files within a model — a theme for later development (cf. Stitch). Finally, the fact that org-mode is tightly integrated with Emacs — the tool used for the majority of software development in MASD — is a very important point and goes to the heart of our ideas on pervasive integration (the Integration Principle); modeling should be integrated as tightly as possible with existing developer workflows.21
By this we are not stating that all developers working on MASD should use Emacs or even org-mode; instead, they should either perform a similar analysis to the present one, figuring out how to best integrate modeling to their workflow, or find ways of using org-mode with their current setup.
The codec name is not of great significance in the near future as it is only used internally, and as a way to name the set of conventions MASD has created for its org-mode documents. As a future direction, we would like to add org-model specific support to Emacs to facilitate the authoring of org-model diagrams.
Using org-roam to enable cross-document referencing appears to be a fruitful way with which to address this issue, though additional analysis still remains on how best to perform this integration.