MASD Reference Implementation
Table of Contents
High-level models are quite different from programs in conventional programming languages. They abstract from most of the detail that a programming language exhibits. Once you want to generate real code, all this detail has to be filled in. This makes code generation from those models a difficult task. Moreover, many decisions in this process are similar for different target languages, but it is hard to make use of these commonalities. — Piefel and Neumann (Piefel, Michael and Neumann, Toby, 2006)
It's hard to overestimate the importance of the MASD Reference Implementation (MRI) to MASD; it is a key component of the methodology, playing three distinct roles. First, due to our reliance on dogfooding (cf. Section The MASD Methodology), all ideas and features must be battle-tested in the MRI before they can be incorporated and exposed to end users; in this guise, the MRI acts as their litmus test.1 Secondly, the MRI is the de facto standard for anything not covered in the present document (cf. The MASD Methodology). This includes core elements such as the MASD UML profile, non-structural variability definitions, the menu of supported codecs and much more. Finally, and perhaps most significantly, the MRI supplies the tooling needed by end users in order to apply MASD to their own software projects.2
The MRI is a software product line presently composed of three individual products. This chapter will present an overview of each of these, as follows. Section Dogen covers Dogen, the code generator, and contains the bulk of the chapter's material. Section Reference Products discusses the two reference products for each of the supported TS's (C++ and C#). The chapter ends with a discussion of the lessons learned with the MRI (Section Evaluation). Let us then start with the software project at the root of it all.
Dogen
Dogen3, the domain generator, is a FOSS project implementing a code generator based on MDE principles and is deeply interwoven with MASD, as this section will explain. The scene will be first set by discussing the historical context and the motivation for the project (Section Historical Context). Section Requirements then discusses the additional requirements the tool had to satisfy, followed by Section Software Development Methodology which elaborates on the SDM used to deliver those requirements. Section Architecture provides a brief summary of its implementation details, including its architecture, and relates it back to MASD's own domain architecture (the Domain Architecture chapter). Section Basic Usage concludes Dogen's synopsis by taking on end user concerns such as tool usage and application, and supplies a quick tour of the main features of the command-line tool.
Historical Context
Dogen was started in 2011 by the author of the present document, who acts as both its maintainer and main contributor. Dogen has been in continuous development since inception, with a frequent if somewhat irregular release cadence, totalling 130 releases over the decade-long span — 110 of which are publicly available. Figure 1 shows the distribution of releases per year, starting in 2012, which is the year the project was first made available in GitHub.4 Its latest release is v1.0.30, published at the start of January 2021.8 Focus then shifted towards completing the present document, meaning no further releases have been made since.
An important aspect in our drive towards the productionisation of Dogen has been the consolidation of the requirements for the tool. Further to the requirements laid out in Requirements for a New Methodology — mainly driven by theoretical considerations — more practical concerns have been added, as described next.
Requirements
Dogen introduces four additional non-functional requirements which significantly constrain the set of choices for its implementation; of these, three are refinements of what has already been outlined in Requirements for a New Methodology. They are as follows:
- Performance requirements. Generating all its models must not take longer than 5 seconds, and running the entire test suite — including regenerating all of the C++ and C# reference implementation models (cf. Section Reference Products) — must not take over 10 seconds. Whilst somewhat arbitrary, these numbers were chosen as an acceptable upper bound on wait time during development. Higher values would result in a degradation of the edit-compile-run cycle, negatively impacting developer experience.9
- Dependency requirements (furthering of Requirements for a New Methodology). In order to facilitate integration to development environments, Dogen must be as self-contained as possible. This means it cannot necessitate the installation of run times such as JVM or the CLR, as these would act as a further barrier to entry to developers not using those technologies. Thus, only technologies which produce native binaries can be used.
- Cross-platform requirements (furthering of Requirements for a New Methodology). Dogen must support all of the main platforms used by developers. These include Windows, Linux and Mac OS X (OSX). The code base must support compilation across all of these platforms, implying that the generated code must also have cross-platform support.
- Integration requirements (furthering of Requirements for a New Methodology). Finally, Dogen must supply a library with access all of its functionality; the library can be used as a basis to extend existing programming environments. In order to make the library compatible with any of the myriad of technologies used to engineer development environments, the interface should be available on a low-level programming language such as C. This is because binding C interfaces into any of the modern languages via tooling such as SWIG (Marco Craveiro, 2021a) (Section 5.3) is a straightforward exercise.
These non-functional requirements stem in no small part from our own experiences in developing MDE tooling (Marco Craveiro, 2021a), as well as our reading of the adoption literature (cf. The State of MDE Adoption), where performance and disregard for developer workflows are often cited as pitfalls. Furthermore, the long list of requirements, both functional and non-functional, together with the many phases that the development has gone through (cf. Section Historical Context) are reflective of a difficult search for a solution over a vast problem space. Our choice of SDM proved decisive in leading us through such a long and open-ended search, as the next section will explain.
Software Development Methodology
A cornerstone of Dogen has been its extensive use of agile, in itself a demonstration of how MASD integrates with typical SDMs.10 The practice of sprints has been adopted from inception, with a sprint elapsing around 80-developer hours of effort and culminating with a release. Each sprint has a sprint backlog checked in to version control, documenting all development activity undertaken in the form of stories. Figure 2 captures a fragment of the sprint backlog, showing the time-keeping aspect. Note that whilst publicly accessible, the sprint backlog is meant mainly for internal consumption.

Figure 2: Fragment of sprint backlog for Dogen's 130th sprint.
The second salient aspect of our agile approach has been the use of retrospectives.11 Lacking traditional forms of interaction and validation that come naturally with being part of a wider engineering team, we turned instead towards publishing online content in order to emulate this feedback loop. Unlike the sprint backlog, the material produced in this context is meant for external consumption, and so provides the additional background required by a lay audience. As part of this outreach effort, detailed release notes have been authored from 2016 onwards, made available in the project's repository.12 The release notes provide user-friendly descriptions of the main stories carried out, discussing trade-offs and supplying a rationale for the changes, as well as providing links to a video demonstrating the changes. Figure 3 is taken from v1.0.30's release notes, and shows a graphical summary of development effort across stories, measured as story duration as a percentage of total sprint duration.13 Release notes and other online material has helped enormously as Dogen progressed through the development phases (cf. Section Historical Context).
Architecture
Dogen is written entirely in the C++ programming language, chosen specifically
to meet our non-functional requirements, particularly with regards to
performance and dependencies (cf. Section Requirements).
The decision had the unfortunate side-effect
of closing the doors on a plethora of MDE tooling, platforms and
libraries — such as EMF and T4 — as they are often written
in Java or C#.14 This helps explain Dogen's size, weighing in at
just under 150 thousand LOC, as measured by the sloccount
tool.15
Figure 4: Collage of all Dogen models in a UML representation.
On the other hand, around 50% of the total line count is generated by Dogen
itself, and all components of Dogen are modeled as Dogen models. Figure
4 shows a collage of all
seventeen Dogen models in Dia's UML representation, prior to their move
to org-model format (cf. Literate Modeling with org-model). Though perhaps not
particularly helpful with regards to detail, its bird's eye view does portray
adequately the size and complexity of the application, as well as demonstrating
the use of colour in our UML diagrams (the Domain Architecture chapter).
Figure 5 zooms in on the largest of these components,
dogen.logical, implementing the LMM (the Domain Architecture chapter).
Each component in Figure 4 represents a distinct sub-system within Dogen, with a well-defined set of responsibilities. What follows is a summary of the components, with a reference back to MASD's domain architecture (the Domain Architecture chapter) where applicable.
dogen.codec: (the Domain Architecture chapter) contains the codec framework and its associated transform chains. It is responsible for the extraction of modeling information from foreign TSs, and converting them into the simplified codec representation. It collaborates with external platforms (e.g. for JSON) or internal components (e.g.dogen.dia,dogen.org) to read the external representations. For certain limited cases it also provides extraction support — at present org-mode and PlantUML.

Figure 5: UML representation of Dogen's logical model.
dogen.dia: internal implementation of the Dia object model, including a parser that uses an XML library to read Dia diagram files. The library is asymmetric — that is, it can only read diagrams.dogen.org: internal implementation of an org-mode parser. Contains all of the domain objects representing org-mode entities, as well as transforms that convert from and to this representation.dogen.identification: defines all identifiers across LPS dimensions (i.e, logical, physical and variability dimensions), as well as identifiers for codecs, used in projections across these spaces (the Domain Architecture chapter).dogen.logical: implements the logical dimension of the LPS (the Domain Architecture chapter), as well as supplying all the transformations required to process logical elements (bottom left in Figure 5).dogen.physical: implements the physical dimension of the LPS (the Domain Architecture chapter), and contains all the transformations required to generate files in the filesystem. Also contains an implementation of the PMM, encoding with it at compile time the geometry of physical space. Conceptually, this can be thought of as a reflection layer on the physical space, allowing us to query it at run time — e.g., "list all facets for the C++ TS", etc.dogen.variability: implements the variability dimension of the LPS — i.e., the VMM (the Domain Architecture chapter) — and contains all of the transformations required to extract configurations from any of the supported consumer models (i.e.dogen.logical,dogen.physicalanddogen.codec).dogen.profiles: contains the configuration for the Dogen product, instantiating the VMM and defining the configuration language for Dogen.dogen.text: projection framework that takes logical model elements and generates their physical representation. These are implemented as M2T transforms, defined using the internal text templating languages discussed next.dogen.templating: provides the two templating engines used throughout Dogen. The first one is a trivial implementation of the mustache logic-less templates16 and is expected to be replaced in the near future by a platform library such asmstch.17 The second templating engine is called stitch, and it is used to create M2T transforms (cf. Section Stitch).dogen.tracing: provides transform tracing infrastructure. When enabled, the tracing sub-system creates trace dumps of model state before and after transform execution as text files in JSON format. These files can then be diffed using command line utilities such asdiffor further processed with tools like JQ18, which specialises in JSON processing.dogen.relational: provides a RDBMS backend for the tracing sub-system, allowing trace data to be stored in database tables. However, at present, the information is stored as JSON documents, making querying difficult. Further work is required in order to fulfil the initial promise of this approach, making deeper use of the relational model. It will also serve as an improved test of the ORM support in Dogen.
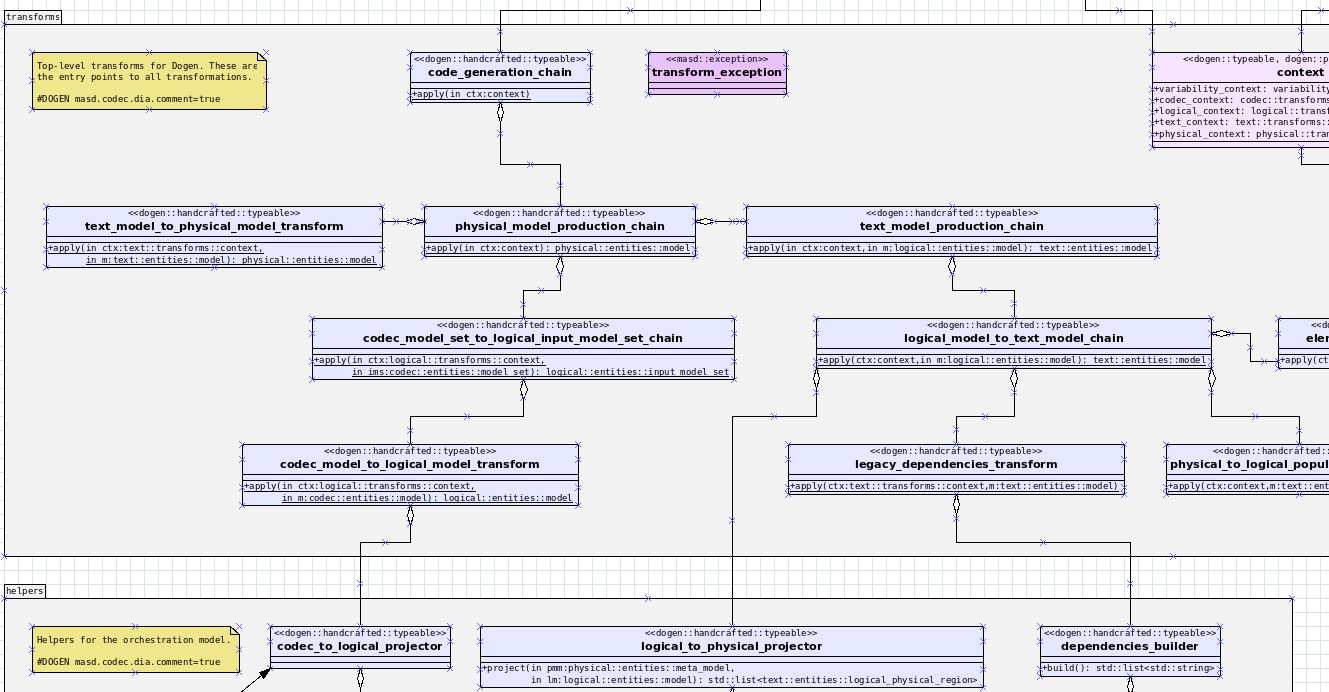
Figure 6: Fragment of Dogen's orchestration model with transforms.
dogen.orchestration: orchestration engine for Dogen that creates the top-level transformation chain, calling out to each sub-system as required. It is responsible for creating the pipeline that converts from a codec representation, to a logical model representation and finally to the physical representation. Figure 6 shows a fragment of the transforms defined in the orchestration model.dogen.utility: assorted utility functions such as logging, XML processing, testing helpers and other miscellaneous functionality.dogen: the API model. Contains the top-level entry point to Dogen. This component will be exposed as a library via SWIG using a language such as C, to enable bindings for a number of programming languages.dogen.cli: implements the command-line driver for Dogen. This is the application entry point from a coding perspective, if using Dogen as a stand-alone tool.
Most of these subsystems have complex implementation details which cannot be
adequately covered in the present manuscript. We shall, however, look into one
such subsystem because it offers some insight on the overall approach. This is
the templating language used in dogen.text.
Stitch
As previously mentioned (cf. Application Evaluation), Dogen has
support for a text templating language which can be embedded into org-mode
source code blocks. This language was implemented specifically for Dogen, and
now binds closely to its use cases. Its
syntax is inspired by Microsoft's T4, a text templating engine popular
in industry (e.g. (Marco Craveiro, 2021)). Figure
7 depicts a small fragment of a larger text template
defined in the dogen.text model.
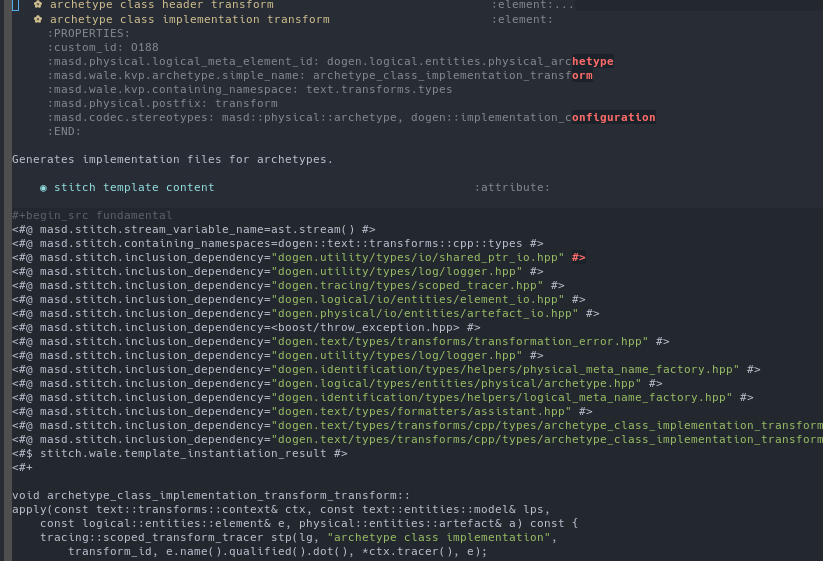
Figure 7: Fragment of a stitch text template in the text model.
As explained, stitch was created because T4 was unavailable for our development stack. In its initial incarnation, stitch was envisioned as a stand-alone tool that pre-processed a set of text templates and generated compilable C++ code, acting like a cartridge in a cartridge pipeline (the Domain Architecture chapter). However, as the problem domain became better understood over the years, stitch was wired ever more closely to the domain architecture, to the point where its templates are now modeled in the LMM and the external templating tool has been removed altogether. The process leading to the current state of affairs is instructive, as it has implications for cartridges in general.
Applying the physical modeling process (cf. The MASD Methodology) to stitch's text templates revealed these contained a great deal of SRPP's. In addition, the analysis also demonstrated templates could be simplified in two significant ways:
- Reducing the variability surface: given that their purpose is solely to create M2T transforms for Dogen's transform framework, they need not cater for general use cases like T4 does. The generated code can thus be hard-coded to fit precisely the transform framework, minimising the use of non-structural variability to a few select cases. Doing so reduces considerably the size of each template.
- Reusing metamodel information: adding stitch to the LMM gives access to a wealth of information about modeled types, such as their relationships (the Domain Architecture chapter). This removes the need for handcrafting relations in the template, as well as any other parameter that can be inferred from the metamodel and its instances such as the boilerplate, etc.
In summary, though in an initial stage stitch was deemed to be outside MASD's remit — as stipulated by its core values, and the Narrow Scope Principle in particular — over time it was shown to be an integral part of the approach. This is a general trade-off that will be faced with all cartridges: there are obvious benefits of keeping their functionality external to Dogen, reducing the tool's footprint. On the other hand, tighter integration has many benefits, such as improving the overall user experience.19 And it is to the user experience that we shall turn to next.
Basic Usage
The present section gives a brief overview on the command line tool supplied
with Dogen, dogen.cli. In order to it, you must first
install the Dogen package. Packages for supported operative systems are
available for download from the release notes, at the bottom, as shown in Figure
8.20 GitHub is the recommended
provider, as BinTray will be decommissioned in the near future.
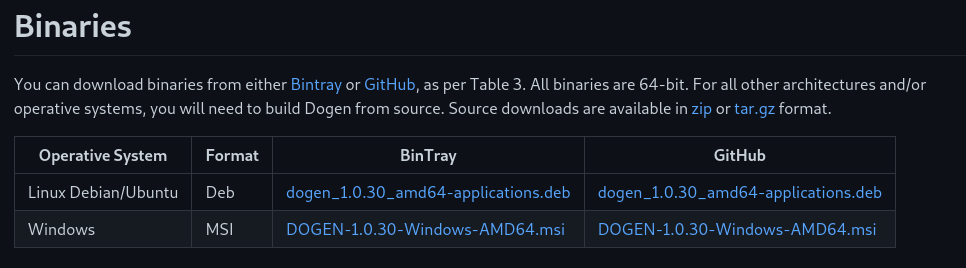
Figure 8: Binary downloads section in Dogen's release notes.
The installation process is as per native packages in each operative system; for example, for Debian GNU/Linux, the installation can be performed using the root user, as follows:
# dpkg -i dogen_1.0.30_amd64-applications.deb Selecting previously unselected package dogen-applications. (Reading database ... 625869 files and directories currently installed.) Preparing to unpack dogen_1.0.30_amd64-applications.deb ... Unpacking dogen-applications (1.0.30) ... Setting up dogen-applications (1.0.30) ...
Once installed, the application should be ready to use by regular users. You can
validate your installation by running the command dogen.cli with --version
or --help. The below listing shows the truncated output of the --help
command.
$ dogen.cli --help Dogen is a Model Driven Engineering tool that processes models encoded in [...] Dogen is created by the MASD project. dogen.cli uses a command-based interface: <command> <options>. See below for a list of valid commands. Global options: General: -h [ --help ] Display usage and exit. -v [ --version ] Output version information and exit. Output: --byproduct-directory Directory in which to place all of the byproducts of the run such as log files, traces, etc. Logging: -e [ --log-enabled ] Generate a log file. -l [ --log-level ] arg What level to use for logging. Valid values: trace, debug, info, warn, error. Defaults to info. [...] Commands: generate Generates source code from input models. convert Converts a model from one codec to another. dumpspecs Dumps all specs for Dogen. For command specific options, type <command> --help.
A model is required in order to drive the tool. A trivial model is supplied with
Dogen for this purpose, called hello_world.org. Figure 9
shows its org-mode representation which, though simple, still deserves a closer
inspection. First, there are several of configuration options at the model
level, as follows:
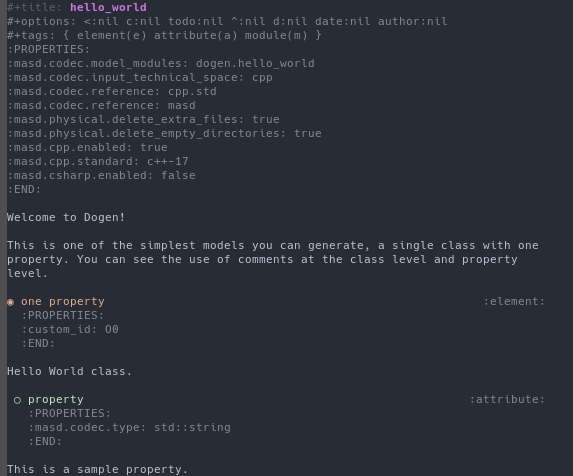
Figure 9: Example Hello World model in org-model notation.
- the model targets the C++ input TS (e.g.,
input_technical_space). Amongst other things, this enables C++ notation for specifying types, such asstd::string. When targeting the C# TS, C# notation must be used instead (e.g.System.DateTime). - the model references two additional models:
cpp.stdandmasd. The first is a PDM that gives access to C++ Standard Library types such asstd::string. The second model contains MASD infrastructural types, providing support for decorative elements such as modelines, licences, etc. (the Domain Architecture chapter). - both the deletion of extra files as well as of empty directories have been disabled. Doing so delegates the management of artefacts to the user. As we move up the generation levels towards product family generation (Level 4), all of the filesystem management features should be enabled, allowing Dogen manage all artefacts in the filesystem for the user (cf. The MASD Methodology).
- the code generator will output C++ code (i.e.
masd.cpp.enabledis set totrue) but it will not output C# code (i.e.masd.csharp.enabledis set tofalse). The version used for C++ is 17.
The model then defines a single element which, via defaulting, results in the
instantiation of a masd::object LMM entity, containing a single
property called one property. To help visualisation, Figure 10
depicts the same model in UML
notation as created by PlantUML, from a Dogen-generated source. Documentation is
used both at the model level, the element level and the property level, some of
which visible in the PlantUML representation as UML notes.

Figure 10: Example Hello World model in UML notation.
It is also useful to visualise the literate modeling view. Figure 11 does so by displaying the PDF output of the model as generated by org-mode. Note that, for the purpose of this simplistic example, we rely on org-mode's default configuration, resulting on a less visually appealing document; for example, the red boxes representing hyperlinks to document sections can be configured to use a more idiomatic link notation. In addition, as explained in Literate Modeling with org-model, spaces in headlines are allowed by Dogen to facilitate literate modeling; internally, headline titles are normalised to valid identifiers according to a selected scheme, involving for example converting spaces to underscores.

Figure 11: Example Hello World model as a PDF document.
Calling dogen.cli with the generate command produces source code for this
model, as per listing below. Full logging at log level trace is also enabled
in the example, which is the highest. It is a useful setting for troubleshooting
— as are other options such as
transform tracing — but these are not to be used unless required, for they
have a significant impact on execution speed. After running the command, all
byproducts such as logs and trace files are stored under the directory
dogen.byproducts, whereas generated source code is saved in the component
directory dogen.hello_world.
$ dogen.cli generate -t hello_world.org --log-enabled --log-level trace $ ls -l total 9 drwxr-xr-x 3 marco marco 4096 2021-09-01 17:10 dogen.byproducts drwxr-xr-x 5 marco marco 4096 2021-09-01 17:10 dogen.hello_world -rw-r--r-- 1 marco marco 940 2021-09-01 17:10 hello_world.org
As we used the default directory structure and naming, and since all facets in the C++ region of physical space are enabled, the directory tree generated in the filesystem is a simple reflection of the geometry of the PMM (the Domain Architecture chapter) in this region:
$ tree --charset nwildner . |-- dogen.byproducts | `-- cli.generate.hello_world.org | `-- cli.generate.hello_world.org.log |-- dogen.hello_world | |-- generated_tests | | `-- one_property_tests.cpp | |-- include | | `-- dogen.hello_world | | |-- hash | | | `-- one_property_hash.hpp | | |-- io | | | `-- one_property_io.hpp | | |-- odb | | | `-- one_property_pragmas.hpp | | |-- serialization | | | |-- one_property_fwd_ser.hpp | | | `-- one_property_ser.hpp | | |-- test_data | | | `-- one_property_td.hpp | | `-- types | | |-- hello_world.hpp | | |-- one_property_fwd.hpp | | `-- one_property.hpp | `-- src | |-- hash | | `-- one_property_hash.cpp | |-- io | | `-- one_property_io.cpp | |-- odb | | `-- one_property_options.odb | |-- serialization | | `-- one_property_ser.cpp | |-- test_data | | `-- one_property_td.cpp | `-- types | `-- one_property.cpp `-- hello_world.org
Enabled facets include hash, io, odb, etc.21 For
completeness, we'll also have a peek at one of the generated files, the type
definition of one_property.hpp shown below. As decoration-related options were
not selected — such as licence, modeline and so on — no decoration was
generated. For the same reason, default methods have
been outputted, such as the "complete constructor" — a constructor that takes
all properties as arguments, which in this case is just property. Dogen
supplies a large number of options to control the generation of these constructs
via non-structural variability, but for simplicity all of these have been
omitted.
#ifndef DOGEN_HELLO_WORLD_TYPES_ONE_PROPERTY_HPP #define DOGEN_HELLO_WORLD_TYPES_ONE_PROPERTY_HPP #if defined(_MSC_VER) && (_MSC_VER >= 1200) #pragma once #endif #include <string> #include <algorithm> #include "dogen.hello_world/serialization/one_property_fwd_ser.hpp" namespace dogen::hello_world { /** * @brief Hello World class. */ class one_property final { public: one_property() = default; one_property(const one_property&) = default; one_property(one_property&&) = default; ~one_property() = default; public: explicit one_property(const std::string& property); [...] public: /** * @brief This is a sample property. */ /**@{*/ const std::string& property() const; std::string& property(); void property(const std::string& v); void property(const std::string&& v); /**@}*/ public: bool operator==(const one_property& rhs) const; bool operator!=(const one_property& rhs) const { return !this->operator==(rhs); } public: void swap(one_property& other) noexcept; one_property& operator=(one_property other); private: std::string property_; [...]
The source code listing concludes our brief overview of Dogen. Many features have been left out due to space constraints, such as C# support, as did the advanced usage of the code generator. Presently, the best example of Dogen's usage is Dogen itself, so the interested reader is directed to the project in GitHub. The next section will perform a brief overview of the testing framework used in the MRI, centred around reference products.
Reference Products
Originally Dogen tried to make use of all of its features within the main code base, in keeping with our views on dogfooding. Eventually, as the number of features increased, it became impractical to continue doing so, resulting in the introduction of test models. At the start, all test models were kept with the Dogen code base to facilitate project management. Unfortunately, as the code base became larger, it became unfeasible to continue using this mono-repository approach due to long build times and checkouts; at this point, all test code was separated into its own repositories.
As our understanding of the theory improved this approach was shown to be the correct one, and so a reference product was assigned to each supported TS. The purpose of the reference product is to exercise all features available on a TS, for three interrelated reasons:
- Conformance: reference products fulfil MASD's requirements around conformance testing (cf. Requirements for a New Methodology), ensuring that all supported features are working as specified. Dogen runs a suite of unit tests that regenerate all reference products in its CI/CD pipeline, to ensure correctness.
- Test-Driven Development (TDD): features must be added to the reference models first, with the Dogen code base being subsequently updated to get the tests to pass. In the future, as we expand to external users, the expectation is that they will create MWE's by changing the reference models via change requests as part of the MRI Development Process (cf. Section Software Development Methodology).
- Documentation and Samples: reference products serve as samples for new users who wish to gain a better understanding of Dogen's capabilities. As these products do not have any additional behaviour, they are "bare-bones" demonstrations of specific Dogen features.
Note that the Dogen code base is still deemed as vital for both conformance testing as well as a form of documentation for advanced use cases; and all features that are not intended to be user facing are only tested within Dogen models. The size of this feature set is still considerable because a significant portion of Dogen exists only to satisfy Dogen's internal use cases. Amongst many other features, this includes the transform framework and its integration with stitch (cf. Section Stitch). In other words, since we could not cover all supported features and since its use cases are too advanced for new comers, Dogen is seen as a second line of defense rather than the primary mechanism for these aspects.
The reference products are named after the TS they cover:
cpp_ref_impl is the C++ Reference Implementation — now known as the C++
Reference Product — and CSharpRefImpl is the C# Reference Implementation
— now known as the C# Reference Product. The next two section provide a brief
overview of each product.
C++ Reference Product
At just over 85 thousand lines of code, 90% of which code-generated, the C++ Reference Product is the largest reference product of the MRI. It is composed of a number of component models, which can be described by grouping related functionality.
- Facet enablement tests: A number of models are used just to ensure that
enabling and disabling facets works as expected. These include
enable_facet_hash,enable_facet_ioand so on, with all models following the same naming convention. - Platform tests: Some models test the integration with PDMs, such as
the C++ Standard Library (
std_model) and the Boost C++ library22 (boost_model). In general, for each new PDM added, there should be an associated PDM component to test it. - Language features: The
cpp_modelis responsible for testing the core features supported in the C++ language. It covers only the latest stable version, C++ 17. In the future, this model will be renamed to take the version into account. We also havecpp_98to validate our support for a legacy version of C++. - MASD-levels support: Dogen has a number of configuration options
designed to support the varying usage levels defined by MASD (cf.
The MASD Methodology), including
force_write,delete_extraandout_of_syncto check for the deletion of unmanaged files,disable_facet_foldersto check for the flattening of the directory structure,ignore_extrato check that we ignore unmanaged files when requested via regular expressions,skip_empty_dirsto test our management of empty directories, etc.
C# Reference Product
The C# reference product, CSharpRefImpl, has the same aims as the C++
reference product but the feature coverage is not symmetric across
TSs. Its much smaller size in LOC is indicative of this
asymmetry: 12 thousand versus 85 thousand. This is to be expected: the C++
TS is the main target of our work because Dogen relies on it directly;
conversely, C# was introduced largely as a device to protect ourselves against
hard-wiring the domain architecture and implementation to a specific
TS.
At present, the product is composed of the following component models:
CSharpModel: Tests the C# language, and a small number of types from the base library. There is no separation between language and library for the moment because we only support a small number of types from C#'s Base Class Library.DirectorySettings: C# version of the directory settings model, with the same objectives as the C++ version — to exercise all features related to the configuration of the PMM.LamModel: C# version of the Language Agnostic Model, the test model used to verify PIM functionality.
Our product backlog has a series of stories related to missing features in C# support, most of which are on the roadmap for the v2.0 release. As part of the work on implementing those features, the C# reference product will be augmented with the missing test components — making it similar in shape to the C++ reference product.
These words conclude our brief introduction to the MRI product line. The next and final section of the chapter discusses the lessons learned by implementing Dogen and the reference products.
Evaluation
Dogen is the main application of both MASD and the MRI, which is to say of Dogen itself, giving us firm grounds from whence an evaluation of both methodology and tooling can be performed. As with org-mode (cf. Evaluation), our conclusions are split between the application (Section Application Evaluation) — that is, the use of the methodology and tooling from the perspective of a regular user — and meta-application (Section Meta-application Evaluation) — that is, how the development of Dogen impacted the methodology as a whole.
Application Evaluation
By far, the biggest problem faced with Dogen application as a user were the frequent stalls due to fundamental issues with the tool, either at the architectural level or with its conceptual framework. In many cases, these issues have taken long periods of time to be addressed adequately, as the size and complexity of the present document attests. As explained at length in (Marco Craveiro, 2021), the creation of MDE tooling is an extremely expensive exercise in general, and it is a cost most software companies are unwilling to absorb. Dogen's development has demonstrated precisely why it is so. From the perspective of more than two decades of industrial software engineering, it is our firm opinion that a project such as Dogen could not be achieved within an industrial setting because the pressure to deliver working products would not allow for the necessary time on fundamental research.
The "stop-start" development also had a negative impact on Dogen itself; we have often been side-tracked when implementing a given story due to one or more missing features in the tool, the implementation of which also required adding additional features, creating a recursive loop that continued several levels deep. As a result, it proved very difficult to keep a focus on the features being implemented. A small example should suffice to give a flavour of the dilemmas faced:
- Whilst trying to add code generation support for PMM entities, such as facets, parts, etc., we ran into a limitation on how stitch templates were handled via an external tool.
- In order to address this problem, we promoted the stitch templates themselves to the LMM as regular metamodel entities. This enabled us to perform a tighter workflow, including the expansion of stitch templates as a regular M2T transform, rather than a cartridge.
- However this then resulted in a new problem: since stitch templates were model elements rather than stand-alone files, it was necessary to extract them in and out of Dia diagrams for editing purposes. The process was cumbersome and error prone, and greatly reduced development velocity.
- Whilst reflecting on this matter, we realised that a long-running org-mode story in the product backlog could be used to solve both problems elegantly, so we implemented org-model (cf. Literate Modeling with org-model).
- Finally, the original task was resumed.
This entire loop took over a year to play out, and many excursions of a similar (or even greater) magnitude were made during the development of Dogen.
On the other hand, these two negative findings reinforce our belief in the approach. No project other than Dogen will need to absorb this large cost once the framework and the methodology have been put in place, provided one is willing to accept MASD's rigid structure. It is a one-off cost that Dogen itself will pay, with subsequent applications having a much smaller cost base because their features are expected to fit in with the existing framework. For example, though not completely trivial, adding a new TS should be a much easier affair in the future, with the main requirement being to follow the patterns supplied in the C++ and C# implementations. In summary, Dogen demonstrates the approach works, but also that it will only be suitable for end users once the tool is mature enough to handle all of its own use cases — leading us to meta-application.
Meta-application Evaluation
It is our firm opinion that the application of MASD to Dogen, and the use of Dogen to develop MASD, has proven the validity of both tooling and methodology. The six core principles of MASD (cf. The MASD Methodology) have been forged in empirical application during Dogen's development, and were selected after many different approaches had been tried; in the same vein, all of MASD processes and actors (cf. The MASD Methodology) have evolved precisely from the continued observation and reflection on the practices within Dogen development — even if somewhat restricted by having a single developer taking on different roles.
Furthermore, we believe that this virtuous cycle was instrumental in shaping both Dogen and MASD (cf. The MASD Methodology), since it allowed us to escape most of the challenges of a dual track process. Whilst not without its flaws — such as the deeply nested recursion described in the previous section, and a risk of over-fitting to Dogen's use cases — in the end, the approach supplied us with a tight feedback loop that removed all distractions that come from having to develop two distinct software products.
In conclusion, dogfooding and bootstrapping aren't merely an expedient approach taken for the development of Dogen; we believe they are a crucial ingredient to the approach, and the main reason why both Dogen and MASD reached its present state.
Bibliography
Brooks, Frederick P (1974). The mythical man-month, Datamation.
Derby, Esther and Larsen, Diana and Schwaber, Ken (2006). Agile retrospectives: Making good teams great, Pragmatic Bookshelf.
Gonz{\'a}lez, AS and Ruiz, DS and Perez, GM (2010). Emf4cpp: a c++ ecore implementation, DSDM 2010-Desarrollo de Software Dirigido por Modelos, Jornadas de Ingenieria del Software y Bases de Datos (JISBD 2010), Valencia, Spain.
J{\"a}ger, Sven and Maschotta, Ralph and Jungebloud, Tino and Wichmann, Alexander and Zimmermann, Armin (2016). An EMF-like UML generator for C++.
Lemma, Remo and Lanza, Michele (2013). Co-evolution as the key for live programming.
Marco Craveiro (2021). Notes on Model Driven Engineering, Zenodo.
Marco Craveiro (2021a). Survey of Special Purpose Code Generators, Zenodo.
Marco Craveiro (2021a). Experience Report of Industrial Adoption of Model Driven Development in the Financial Sector, Zenodo.
Piefel, Michael and Neumann, Toby (2006). A Code Generation Metamodel for ULF-Ware, Humboldt-Universit{\"a}t zu Berlin, Mathematisch-Naturwissenschaftliche Fakult{\"a}t II.
{Marco Craveiro} (2021). Marco Craveiro YouTube Channel.
{Marco Craveiro} (2018). The Refactoring Quagmire.
{Productionisation} (2021). Productionisation — {W}ikipedia{,} The Free Encyclopedia.
Footnotes:
These tests are both literal — in that the MRI contains an automated test suite to validate its features — and conceptual, in that the MRI is expected to have use cases for all relevant aspects of MASD as a methodology. The MRI is primus inter pares of all software products generated using the MRI.
Note that MASD is not against using third party implementations, but at present these do not exist; and when they do, it is likely they will lag behind the MRI. Thus, this option is not considered in the present document.
For completeness, the first public release was v0.20.588. Prior to this release, there had been 19 releases which were not made available to the outside world.
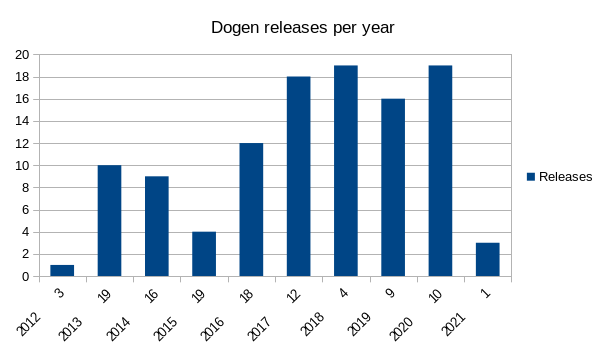
Figure 1: Dogen releases per year.
The current hiatus in development is not uncommon in Dogen's history, as periods dominated by software engineering have been intentionally interleaved with periods dedicated mainly to theoretical work. Looking back on over a decade of engineering, one can divide it into the following phases:
- The second-system effect5 phase (2011 to 2013): Though Dogen was created from scratch, it is conceptually the second iteration of the experiences narrated in (Marco Craveiro, 2021). At inception, a naive belief was held that most of the previous problems were rooted in inexperienced engineering decisions; and that these could be overcome, quickly, via a sounder software engineering approach. To a small extent this conjecture was proved correct, as improvements in the testing framework, parsing and other key areas resulted on an enhanced code generator. However, more issues were created than resolved overall and the architectural complexity increased significantly. By the end of this phase, the magnitude of the original ask was finally understood. As a result, the scope of the endeavour was reduced to a manageable size, and scope narrowing became enshrined in the approach's core values (the Narrow Scope Principle).
- The experimental phase (2013 to 2015): The boundaries may have been set but the internal architecture remained unclear, so the next two years were spent on architectural experimentation. Whilst neither inputs or outputs changed a great deal, the architecture was redesigned multiple times, and all of its components were renamed several times over. As an example, a TS-level model was introduced, using constructs from the supported programming languages directly. Predictably, the approach resulted in failure as the resulting models and associated transforms were too complex. Several other attempts of this ilk were made, and though some of the ideas were kept — most notable of which is stitch, a new text templating language (cf. Section Stitch) — no overall breakthroughs were achieved.
- The research phase (2015 to 2020): This phase begun with the realisation that a strong theoretical foundation was necessary. During this period we familiarised ourselves with the literature on code generation, with a particular focus on MDE, and conducted a formal programme of research that produced the present manuscript as its final outcome. The theoretical foundations for Dogen begun as a series of concepts which were iterated upon for just over 70 releases, until the emergence and consolidation of the domain architecture (the Domain Architecture chapter). This phase included the separation of MASD, the methodology, from Dogen, the tool.
- The productionisation6 phase (2021 onwards): The current objective for Dogen is to add a small number of missing features needed to fully support product line generation, at which point it can be said to have passed the MRI's fitness function (cf. The MASD Methodology). Appropriately, the completion of these features will be marked by the release of Dogen v2.0.7 Subsequent to this release, we will begin to implement some of the many ideas for new features which have been captured over the product's lifetime.
Brooks describes the second-system effect vividly: "This second [system] is the most dangerous system a man (sic.) ever designs. […] The general tendency is to over-design the second system, using all the ideas and frills that were cautiously sidetracked on the first one. The result, as Ovid says, is a 'big pile'." (Brooks, Frederick P, 1974) (p. 55)
Wikipedia tells us that: "Productionisation […] is the process of turning a prototype of a design into a version that can be more easily mass-produced. It is mostly a necessary step in the development of any product, since it is rare that the initial design is free from flaws or construction methods which make it difficult or more expensive to manufacture." ({Productionisation}, 2021)
Originally, we had intended to release v2.0 before publishing the present document. However, there were inevitable delays in coding, which is to be expected given the difficulty in estimating outstanding effort. Since all of the conceptual work had been completed, we opted for finalising the document first and then resuming the programming activities at a later stage.
Though by no means fans of the edit-compile-run cycle, Lemma and Lanza do describe it rather aptly: "Most mainstream programming languages […] are based on the traditional edit-compile-run cycle. This approach allows developers to recognize clear boundaries between the different phases to focus on one activity at a time: first write the code, then compile it, and finally observe and test the system at runtime." (Lemma, Remo and Lanza, Michele, 2013)
For more details on SDMs, including agile, as well as their integration with MDE, please consult Chapter 5 of (Marco Craveiro, 2021).
The term is used in the sense put forward by Derby et al.: "[retrospectives are] a special meeting where the team gathers after completing an increment of work to inspect and adapt their methods and team work. Retrospectives enable whole-team learning, act as catalysts for change, and generate action." (Derby, Esther and Larsen, Diana and Schwaber, Ken, 2006)
The interested reader is directed towards these documents in order to understand the historical context in greater detail. Where available, the release notes also link to associated audiovisual material, produced within the scope of each release. Moreover, all audiovisual material can be accessed via the author's YouTube channel ({Marco Craveiro}, 2021). Finally, assorted blog posts have also been published in the author's blog — e.g., "The Refactoring Quagmire" ({Marco Craveiro}, 2018) — which narrate significant episodes during the before-mentioned development phases.
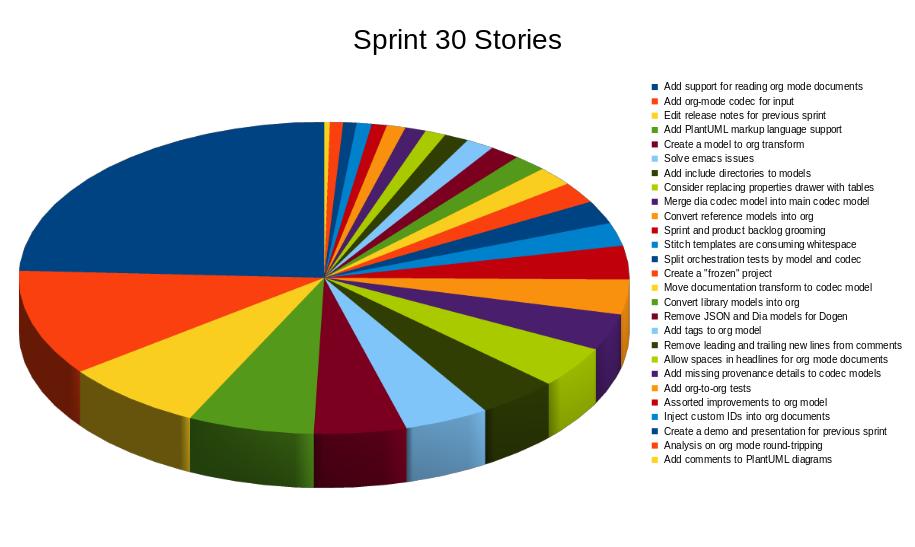
Figure 3: User-facing description of story effort for Sprint 30.
The final but by no means less significant component of our agile approach has been the product backlog. All ideas, thoughts and notes pertaining to Dogen which cannot be immediately acted upon are kept in the product backlog. At present count, it contains just over 800 stories and proto-stories awaiting further attention. The stories in the product backlog are loosely organised into buckets, capturing the notion that some relate to present work whereas others are of a more visionary (or aspirational) nature. Each sprint allocates resources towards grooming the product backlog, thus ensuring its relevance: stories that are no longer required are pruned, duplicate stories are merged and so on, keeping the information up-to-date.
Sprint and product backlogs are connected via the story workflow. Planning for a new sprint begins by moving relevant stories from the product backlog into the sprint backlog. Some stories, such as for example org-mode support (cf. Literate Modeling with org-model), can remain on the product backlog for several years, accumulating more details until they are selected for implementation. In this manner, the product backlog has been vital in organising our search across the problem space, acting as a repository of accumulated knowledge, which reaches its actionable stage in the sprint backlog.
It is a fair assessment to state that Dogen would not have reached its present state were it not for our choice of SDM. Its ability to break down an open-ended problem into a series of small, actionable stories, has propelled us forward, even when the way ahead was unclear. Whilst each sprint delivered only a sliver of change, when aggregated over a ten-year span, the iterative and incremental approach conducted us to the comprehensive architecture we have today — and which the next section will describe, taking us towards implementation-level concerns.
Lack of access to MDE tooling in C++ is by no means a novel problem. Jäger et al. had already encountered this very difficulty in 2016 (J{\"a}ger, Sven and Maschotta, Ralph and Jungebloud, Tino and Wichmann, Alexander and Zimmermann, Armin, 2016), as had González et al. before, six years prior (Gonz{\'a}lez, AS and Ruiz, DS and Perez, GM, 2010). Though differing in the details, both opted for a native C++ port of Ecore, the EMF metamodel. After analysing both implementations, we decided against using either of them due to their complexity (largely a byproduct of Ecore rather than the projects themselves), fears about vendor lock-in (both projects have a small user and developer base) and, most significantly, the fact that Dogen did not require many of Ecore's features such as runtime introspection, for which there is likely a runtime penalty associated. However, we do intend to support Ecore as a codec, allowing users to create their models using EMF and generating them via Dogen. Thus, as future work, we will likely integrate with one of these libraries, but relegating their use to only input (and possibly output).
For example, end users need to install and configure the tooling for external cartridges. At present this is a significant source of accidental complexity for some cartridges such as ODB, due to its complex installation procedures.
Due to issues with our CI/CD provider, Mac OS X builds have been discontinued. This is an issue which will be addressed in the near future. For now only Windows and Linux packages are available, as shown in the screenshot.
The roles and responsibilities of each facet shown are as detailed in see The MASD Methodology.
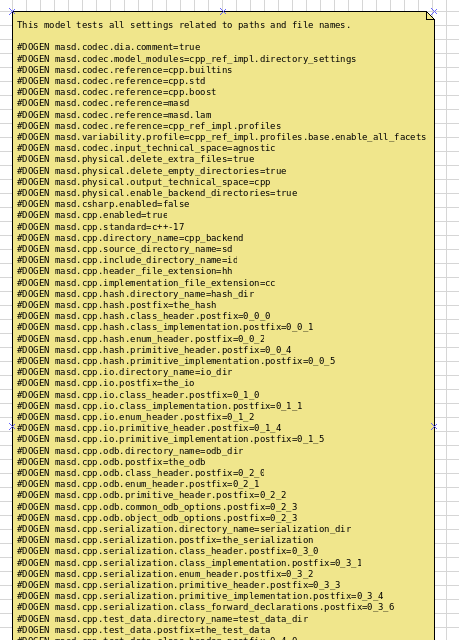
Figure 12: Fragment of the directory settings model configuration.
- Physical configuration: Though somewhat misleadingly named, the model
directory_settingsis responsible for exercising all of Dogen's configuration options regarding the naming of physical entities. Figure 12 contains a fragment of these options. - PIM support: The
lam_modelis designed to generate both C++ and C# code, ensuring our PIM support works as intended — LAM standing for Language Agnostic Model. At present Dogen only supports basic type mapping, with much work still outstanding for PIMs to be considered first class citizens. - Codec-specific features: In some cases we need to validate features that are
only available on a given codec. At present there are two such models:
compressed, which tests compressed diagrams in Dia, andtwo_layers, which contains a Dia model using multiple layers. In general, the policy is to avoid having codec-specific features and, by implication, avoid codec-specific tests, so this group of components is not expected to grow. - RDBMS support: The
northwindmodel exercises Dogen's relational database support, which at present requires ODB. In the future, it may serve as the basis for an implementation that does not rely on a cartridge — an approach which is presently under analysis.